さて、形態要素解析の準備が整っても例文がなければ話にならない。
ということで、Wikipediaのabstract(概要)をコーパスに利用しようと思った。
Wikipediaデータベースダウンロードから
jawiki-20130216-abstract.xml 1.3 GB
をダウンロード
xmlの実際の中身はこんな感じ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
</doc> <doc> <title>Wikipedia: 言語</title> <url>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E</url> <abstract>言語(げんご )とは、コミュニケーションのための記号の体系である。</abstract> <links> <sublink linktype="nav"><anchor>定義</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E5.AE.9A.E7.BE.A9</link></sublink> <sublink linktype="nav"><anchor>自然言語</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E8.87.AA.E7.84.B6.E8.A8.80.E8.AA.9E</link></sublink> <sublink linktype="nav"><anchor>歴史</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E6.AD.B4.E5.8F.B2</link></sublink> <sublink linktype="nav"><anchor>起源</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E8.B5.B7.E6.BA.90</link></sublink> <sublink linktype="nav"><anchor>変化</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E5.A4.89.E5.8C.96</link></sublink> <sublink linktype="nav"><anchor>世界の言語</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E4.B8.96.E7.95.8C.E3.81.AE.E8.A8.80.E8.AA.9E</link></sublink> <sublink linktype="nav"><anchor>言語の数と範囲の不確定</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E8.A8.80.E8.AA.9E.E3.81.AE.E6.95.B0.E3.81.A8.E7.AF.84.E5.9B.B2.E3.81.AE.E4.B8.8D.E7.A2.BA.E5.AE.9A</link></sublink> <sublink linktype="nav"><anchor>各国の国語・公用語</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E5.90.84.E5.9B.BD.E3.81.AE.E5.9B.BD.E8.AA.9E.E3.83.BB.E5.85.AC.E7.94.A8.E8.AA.9E</link></sublink> <sublink linktype="nav"><anchor>普段話されている言語の人口順位(上位10言語)</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E6.99.AE.E6.AE.B5.E8.A9.B1.E3.81.95.E3.82.8C.E3.81.A6.E3.81.84.E3.82.8B.E8.A8.80.E8.AA.9E.E3.81.AE.E4.BA.BA.E5.8F.A3.E9.A0.86.E4.BD.8D.EF.BC.88.E4.B8.8A.E4.BD.8D10.E8.A8.80.E8.AA.9E.EF.BC.89</link></sublink> <sublink linktype="nav"><anchor>国際的に重要な言語の要件</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E5.9B.BD.E9.9A.9B.E7.9A.84.E3.81.AB.E9.87.8D.E8.A6.81.E3.81.AA.E8.A8.80.E8.AA.9E.E3.81.AE.E8.A6.81.E4.BB.B6</link></sublink> <sublink linktype="nav"><anchor>公用語、共通語、民族語</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E5.85.AC.E7.94.A8.E8.AA.9E.E3.80.81.E5.85.B1.E9.80.9A.E8.AA.9E.E3.80.81.E6.B0.91.E6.97.8F.E8.AA.9E</link></sublink> <sublink linktype="nav"><anchor>言語の生物学</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E8.A8.80.E8.AA.9E.E3.81.AE.E7.94.9F.E7.89.A9.E5.AD.A6</link></sublink> <sublink linktype="nav"><anchor>言語に関する脳の領域</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E8.A8.80.E8.AA.9E.E3.81.AB.E9.96.A2.E3.81.99.E3.82.8B.E8.84.B3.E3.81.AE.E9.A0.98.E5.9F.9F</link></sublink> <sublink linktype="nav"><anchor>ヒトの発達における言語機能の獲得</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E3.83.92.E3.83.88.E3.81.AE.E7.99.BA.E9.81.94.E3.81.AB.E3.81.8A.E3.81.91.E3.82.8B.E8.A8.80.E8.AA.9E.E6.A9.9F.E8.83.BD.E3.81.AE.E7.8D.B2.E5.BE.97</link></sublink> <sublink linktype="nav"><anchor>脚注</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E8.84.9A.E6.B3.A8</link></sublink> <sublink linktype="nav"><anchor>関連項目</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E9.96.A2.E9.80.A3.E9.A0.85.E7.9B.AE</link></sublink> <sublink linktype="nav"><anchor>外部リンク</anchor><link>http://ja.wikipedia.org/wiki/%E8%A8%80%E8%AA%9E#.E5.A4.96.E9.83.A8.E3.83.AA.E3.83.B3.E3.82.AF</link></sublink> </links> </doc> <doc> |
xmlを見てわかるようにabstractタグに概要が含まれている。そして、()の間によみがなや英字が書かれる。
DOMでの失敗
正直こんな初歩的な失敗をするのは私のようなアホだけだと思う。
私はまず次のように書いた。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import xml.dom.minidom import re if __name__ == "__main__": dom = xml.dom.minidom.parse("jawiki-20130216-abstract.xml") f = open("abstract.txt","w") for url in dom.getElementsByTagName("abstract"): """半角、全角カッコ双方を消去""" abstract = re.sub(r'[((].+?[))]', '', url.firstChild.data) lines = abstract.split("。") for line in lines: f.write(line+"\n") f.close(); print("finished") |
abstractだけ取り出して、カッコを消去して一文ずつ並べる。
短いテストファイルで成功したのを確かめると、wikipediaの1.3GBあるxmlをぶち込んだ。
その結果……
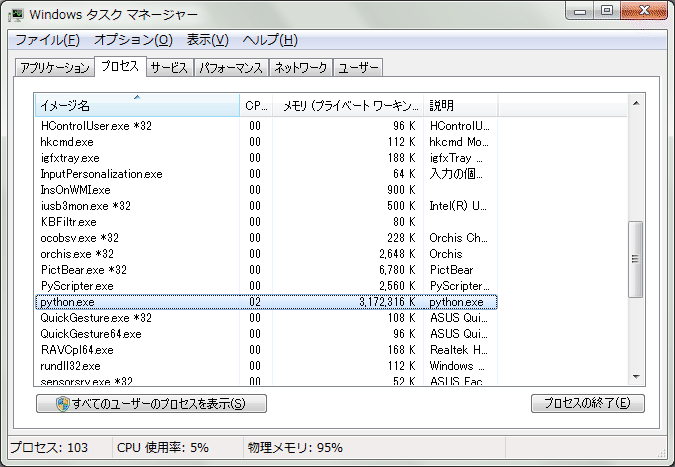
ふぇぇ、めもりいっぱいだよぉぉぉぉぉ
しかも実行が終わらない。
今まで、ここまで大きなxml扱ったことないから気にしたことなかった。
メモリ上に木構造でドンっと置かれてしまうから巨大なXMLはやばい。
lxml3.1.0を用いた解決
Pythonで巨大なxmlを処理する方法はいろいろと在るらしい。
結論から言うと、今回メモリの節約はできなかった。
だが、6分で解析仕切ることには成功した
今回はこちらを参考にしてlxmlを用いることにした。
逐次xmlを処理することができるようだ。
lxml3.1.0の導入
環境は
Windows7 64bit
Python3.3
ダウンロードはこちらから。
解凍先のINSTALL.txtには次のように書かれていた。
see the related
FAQ entry _.If you fail to build lxml on your MS Windows system from the signed
and tested sources that we release, consider using the
unofficial
Windows binaries _that Christoph Gohlke generously provides.
簡単に言うと、
「Windows用のバイナリなんて提供しねーよ!自分でビルドできない情弱はここからダウンロードすれば?もちろん非公式だけどな!」
という感じ(だいぶ歪んでるが)。
なんというツンデレ。
一応nmakeで頑張ったんだよ(棒)
ということで64bit版のlxml-3.1.0.win-amd64-py3.3.exeをダウンロード。インストールするだけですぐに使えるようになりました。
至れり尽くせり。でも、もっとよくmake勉強しなきゃなぁ
lxml3.1.0+Python3.3
先ほど示した参考ページやその他のページを見て、コードを書いた。
初めに、サンプルコードを参考に、abstractタグを取り出すため次のように書いた。
|
1 2 |
file = open('abstract.xml','r') xml_iter = lxml.etree.iterparse(file, events=('end',),tag='abstract') |
しかしエラー発生
UnicodeDecodeError: ‘cp932′ codec can’t decode byte 0xef in position 0: illegal multibyte sequence
‘cp932′はPerlの標準出力でさんざん悩まされた、Windowsのコマンドラインの文字コード。
とりあえず文字コード周りを何とかしようと四苦八苦。
import codecs を使ってxmlを文字コード指定読み出ししてみる。
|
1 2 3 4 |
import codecs """略""" file = codecs.open("sample.xml",'r','utf_8') xml_iter = lxml.etree.iterparse(file, events=('end',),tag='abstract') |
しかし今度は
TypeError: reading file objects must return bytes objects
というバイナリで渡してくださいよというエラー。
検索しても解決策が見えず、初心に戻ってlxmlのリリースに含まれるサンプルコードを見たところあっさり解決。
|
1 |
xml_iter = iterparse("sample.xml",events =('end',) ,tag = 'abstract') |
直接パスを渡せばいいのね。
そんな訳で、まだまだ改良が必要なWikipediaの概要を取り出すコード。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import lxml.etree as ET import codecs import re def main(): pass if __name__ == "__main__": iterparse = ET.iterparse f = codecs.open('abstract2.txt','w','utf_8') """消すもの:カッコ・wikiのタグ(|=)""" r1 = re.compile('[\[|((].*?[|\]))]|[|].*?[=]') xml_iter = iterparse("sample.xml",events =('end',) ,tag = 'abstract') for event,elm in xml_iter: abstract = elm.text while elm.getprevious() is not None: del elm.getparent()[0] elm.clear() if abstract is not None: abstract = r1.sub('', abstract) abstract = abstract.replace('。','\n') abstract = abstract.replace(' ','') f.writelines(abstract) f.close(); print("finished") |
メモリ消費量が一向に減らないけれど、一応実行は終わるので使う分には問題ない。
有効な正規表現を考えなければ。
あと、処理前のxmlにlinkとか無駄な要素が多すぎるので、最初にただの文字列処理でサイズ落とせば軽くなるかも。
